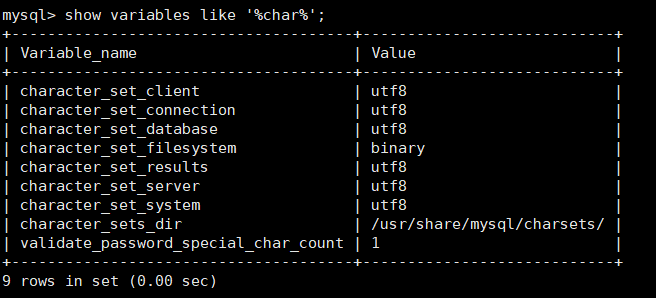
mysql> alter database mydb character set'utf8'; mysql> alter table mytbl convert to character set'utf8'; # 查看数据库的字符集 mysql> show create database 库名 # 创建数据库,顺便执行字符集为utf-8 create database 库名 character set utf8
修改已经乱码数据:
无论是修改 mysql 配置文件或是修改库、表字符集,都无法改变已经变成乱码的数据。
只能删除数据重新插入或更新数据才可以完全解决
[mysqld] # # Remove leading # and set to the amount of RAM for the most important data # cache in MySQL. Start at 70% of total RAM for dedicated server, else 10%. # innodb_buffer_pool_size = 128M # # Remove leading # to turn on a very important data integrity option: logging # changes to the binary log between backups. # log_bin # # Remove leading # to set options mainly useful for reporting servers. # The server defaults are faster for transactions and fast SELECTs. # Adjust sizes as needed, experiment to find the optimal values. # join_buffer_size = 128M # sort_buffer_size = 2M # read_rnd_buffer_size = 2M datadir=/var/lib/mysql socket=/var/lib/mysql/mysql.sock
# Disabling symbolic-links is recommended to prevent assorted security risks symbolic-links=0
# 使用Create单独创建索引 CREATE [UNIQUE] INDEX 索引名 ON 表名(列名[(长度)]); # 使用Alter单独创建索引 ALTER 表名 ADD [UNIQUE] INDEX 索引名 ON 表名(列名[(长度)]); # 删除索引 DROP INDEX 索引名 ON 表名; # 查看某表全部索引 SHOW INDEX FROM 表名;
# ALTER添加主键(主键也是一种索引,意味着该索引值必须唯一,且不能为null) ALTER 表名 ADD PRIMARY KEY(列名); # ALTER添加唯一索引(该索引值必须唯一,允许有NULL) ALTER 表名 ADD UNIQUE 索引名(列名); # ALTER添加普通单值索引(该索引值不一定唯一) ALTER 表名 ADD 索引名(列名); # ALTER添加全文索引(用于全文索引) ALTER 表名 ADD FULLTEXT 索引名(列名);
CREATE TABLE IF NOT EXISTS `article`( `id` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT, `author_id` INT (10) UNSIGNED NOT NULL, `category_id` INT(10) UNSIGNED NOT NULL , `views` INT(10) UNSIGNED NOT NULL , `comments` INT(10) UNSIGNED NOT NULL, `title` VARBINARY(255) NOT NULL, `content` TEXT NOT NULL ); INSERT INTO `article`(`author_id`,`category_id` ,`views` ,`comments` ,`title` ,`content` )VALUES (1,1,1,1,'1','1'), (2,2,2,2,'2','2'), (3,3,3,3,'3','3');
SELECT * FROM ARTICLE;
EXPLAIN SELECT id,author_id FROM article WHERE category_id = 1 AND comments > 1 ORDER BY views DESC LIMIT 1;
CREATE TABLE IF NOT EXISTS `class`( `id` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT, `card` INT (10) UNSIGNED NOT NULL ); CREATE TABLE IF NOT EXISTS `book`( `bookid` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT, `card` INT (10) UNSIGNED NOT NULL ); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20)));
性能分析:
1 2 3 4 5 6 7 8 9
mysql> EXPLAIN SELECT * FROM class LEFT JOIN book ON class.card = book.card; +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+ | 1 | SIMPLE | class | NULL | ALL | NULL | NULL | NULL | NULL | 20 | 100.00 | NULL | | 1 | SIMPLE | book | NULL | ALL | NULL | NULL | NULL | NULL | 20 | 100.00 | Using where; Using join buffer (Block Nested Loop) | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+ 2 rows in set, 1 warning (0.00 sec)
结果:type 为 all
优化:添加索引
左连接将索引添加到右表上,type会扫一个ALL!
1 2 3 4 5 6 7 8 9 10 11 12
mysql> create index idx_card on book(card); Query OK, 0 rows affected (0.10 sec) Records: 0 Duplicates: 0 Warnings: 0
mysql> EXPLAIN SELECT * FROM class LEFT JOIN book ON class.card = book.card; +----+-------------+-------+------------+------+---------------+----------+---------+-----------------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+----------+---------+-----------------+------+----------+-------------+ | 1 | SIMPLE | class | NULL | ALL | NULL | NULL | NULL | NULL | 20 | 100.00 | NULL | | 1 | SIMPLE | book | NULL | ref | idx_card | idx_card | 4 | db02.class.card | 1 | 100.00 | Using index | +----+-------------+-------+------------+------+---------------+----------+---------+-----------------+------+----------+-------------+ 2 rows in set, 1 warning (0.01 sec)
左连接将索引添加到右表上,type会扫一个ALL!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
mysql> drop index idx_card on book; Query OK, 0 rows affected (0.03 sec) Records: 0 Duplicates: 0 Warnings: 0
mysql> create index idx_card on class(card); Query OK, 0 rows affected (0.02 sec) Records: 0 Duplicates: 0 Warnings: 0
mysql> EXPLAIN SELECT * FROM class LEFT JOIN book ON class.card = book.card; +----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+----------------------------------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+----------------------------------------------------+ | 1 | SIMPLE | class | NULL | index | NULL | idx_card | 4 | NULL | 20 | 100.00 | Using index | | 1 | SIMPLE | book | NULL | ALL | NULL | NULL | NULL | NULL | 20 | 100.00 | Using where; Using join buffer (Block Nested Loop) | +----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+----------------------------------------------------+ 2 rows in set, 1 warning (0.00 sec)
结论: 可以看到第二行的type变为了index, rows也变成了原来的20。
这是由左连接特性决定的。
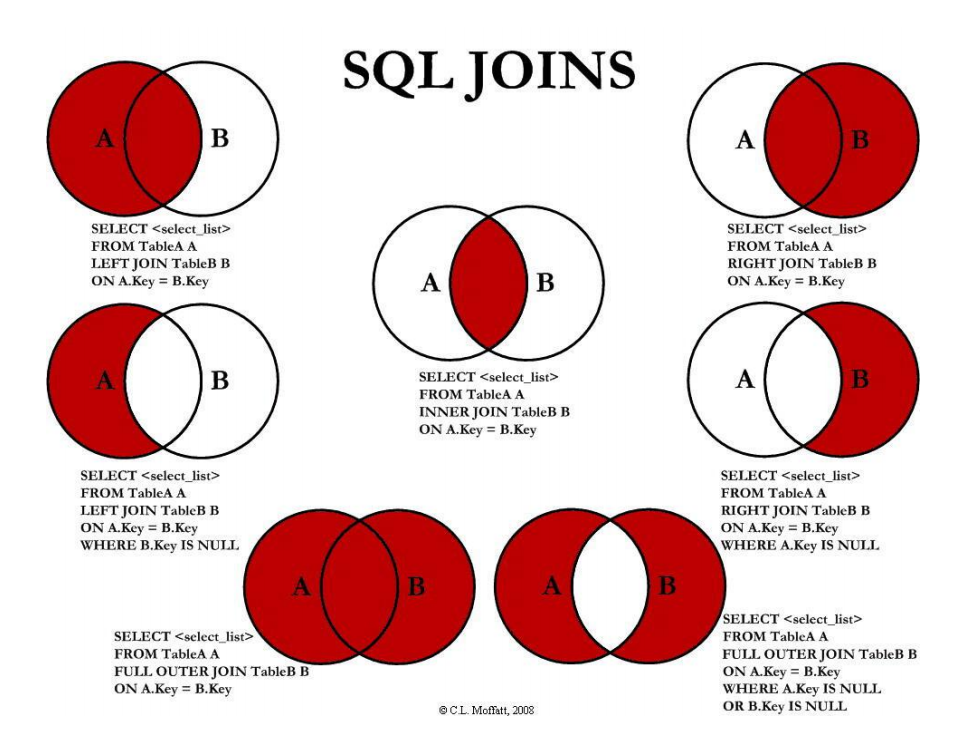
LEFT JOIN 条件用于确定如何从右表搜索行, 左边一定都有,所以右边是我们的关键点,一定需要建立索引。
RIGHT JOIN 条件用于确定如何从左表搜索行, 右边一定都有, 所以左边是我们的关键点,一定需要建立索引。
CREATE TABLE IF NOT EXISTS `phone`( `phoneid` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT, `card` INT (10) UNSIGNED NOT NULL )ENGINE = INNODB;
INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20))); INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20)));
性能分析:
1 2 3 4 5 6 7 8 9
mysql> explain SELECT * FROM class LEFT JOIN book ON class.card=book.card inner JOIN phone ON book.card = phone.card; +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+ | 1 | SIMPLE | class | NULL | ALL | NULL | NULL | NULL | NULL | 20 | 100.00 | NULL | | 1 | SIMPLE | book | NULL | ALL | NULL | NULL | NULL | NULL | 20 | 10.00 | Using where; Using join buffer (Block Nested Loop) | | 1 | SIMPLE | phone | NULL | ALL | NULL | NULL | NULL | NULL | 20 | 10.00 | Using where; Using join buffer (Block Nested Loop) | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+ 3 rows in set, 1 warning (0.00 sec)
结果:type都为ALL,全表扫描
优化:添加索引
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
mysql> create index idx_book on book(card); Query OK, 0 rows affected (0.02 sec) Records: 0 Duplicates: 0 Warnings: 0
mysql> create index idx_phone on phone(card); Query OK, 0 rows affected (0.03 sec) Records: 0 Duplicates: 0 Warnings: 0
mysql> explain SELECT * FROM class LEFT JOIN book ON class.card=book.card inner JOIN phone ON book.card = phone.card; +----+-------------+-------+------------+------+---------------+-----------+---------+-----------------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+-----------+---------+-----------------+------+----------+-------------+ | 1 | SIMPLE | class | NULL | ALL | NULL | NULL | NULL | NULL | 20 | 100.00 | Using where | | 1 | SIMPLE | book | NULL | ref | idx_book | idx_book | 4 | db02.class.card | 1 | 100.00 | Using index | | 1 | SIMPLE | phone | NULL | ref | idx_phone | idx_phone | 4 | db02.class.card | 1 | 100.00 | Using index | +----+-------------+-------+------------+------+---------------+-----------+---------+-----------------+------+----------+-------------+ 3 rows in set, 1 warning (0.00 sec)
结论:
后⒉行的 type 都是ref且总rows优化很好,效果不错。因此索引最好设置在需要经常查询的字段中。
# 建表 CREATE TABLE staffs( id INT PRIMARY KEY AUTO_INCREMENT, `name` VARCHAR(24)NOT NULL DEFAULT'' COMMENT'姓名', `age` INT NOT NULL DEFAULT 0 COMMENT'年龄', `pos` VARCHAR(20) NOT NULL DEFAULT'' COMMENT'职位', `add_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT'入职时间' )CHARSET utf8 COMMENT'员工记录表';
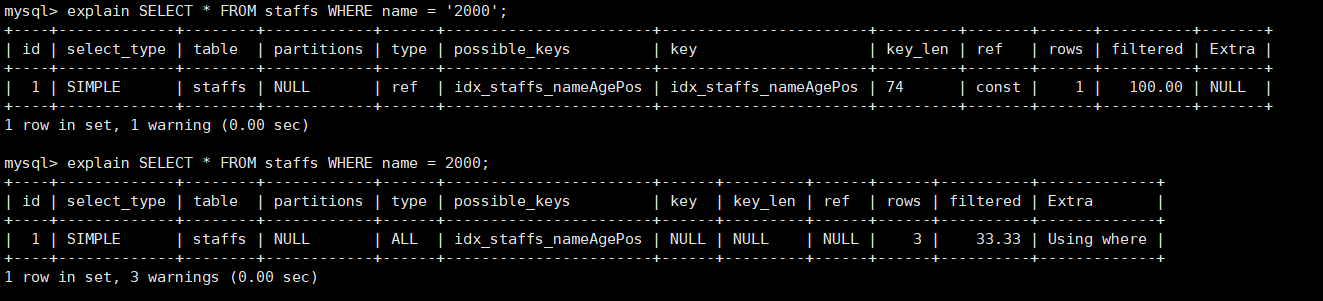
# 插入值 insert into staffs(NAME,age,pos,add_time) values('z3',22,'manager',NOW()); insert into staffs(NAME,age,pos,add_time) values('July',23,'dev',NOW()); insert into staffs(NAME,age,pos,add_time) values('2000',23,'dev',NOW());
# 建索引 create index idx_staffs_nameAgePos on staffs(name,age,pos);
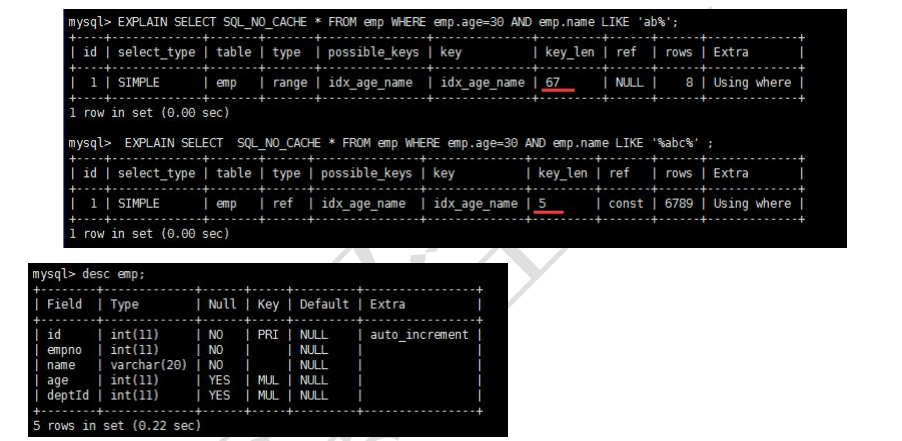
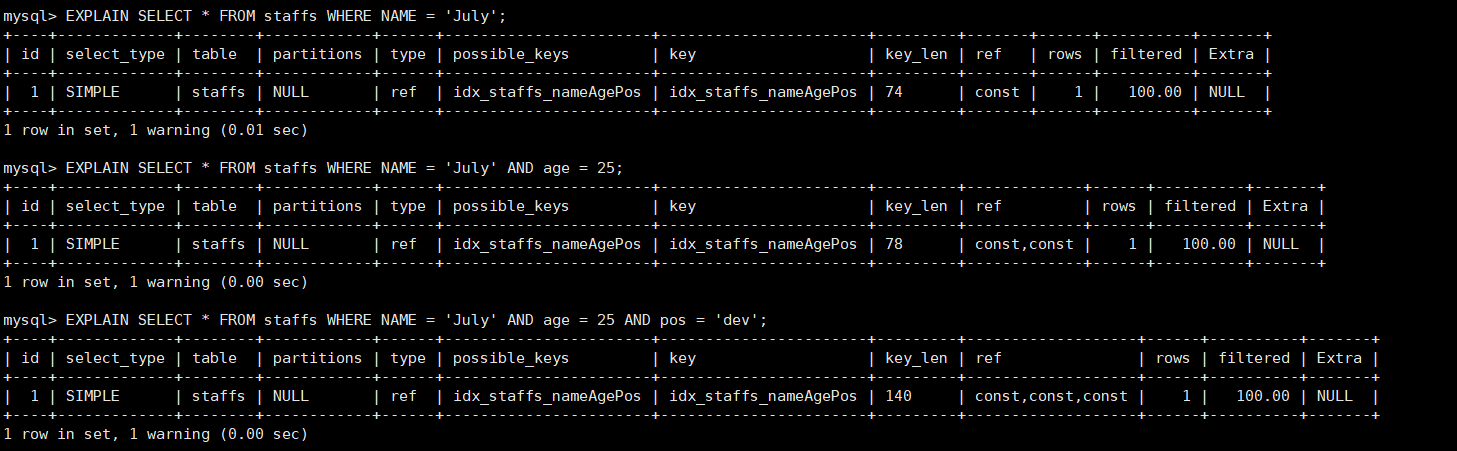
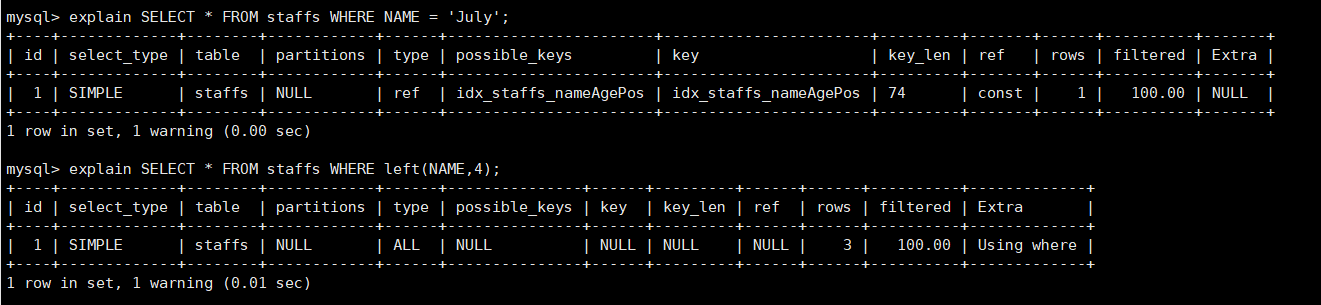
EXPLAIN SELECT * FROM staffs WHERE NAME = 'July'; EXPLAIN SELECT * FROM staffs WHERE NAME = 'July' AND age = 25; EXPLAIN SELECT * FROM staffs WHERE NAME = 'July' AND age = 25 AND pos = 'dev';
type都是ref,ref都是const,精度逐渐增加!
性能分析:
1 2
explain SELECT * FROM staffs WHERE age = 23 AND pos = 'dev'; explain SELECT * FROM staffs WHERE pos = 'dev';
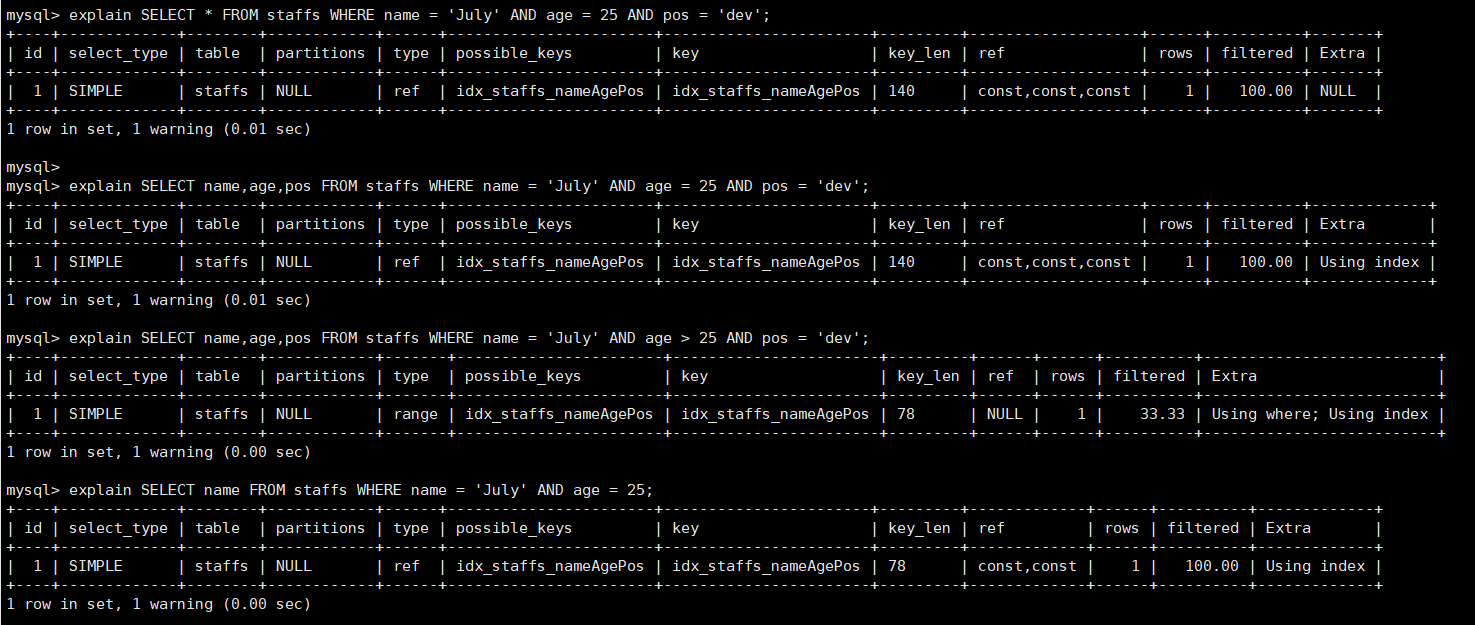
explain SELECT * FROM staffs WHERE name = 'July' AND age = 25 AND pos = 'dev';
explain SELECT name,age,pos FROM staffs WHERE name = 'July' AND age = 25 AND pos = 'dev'; explain SELECT name,age,pos FROM staffs WHERE name = 'July' AND age > 25 AND pos = 'dev'; explain SELECT name FROM staffs WHERE name = 'July' AND age = 25;
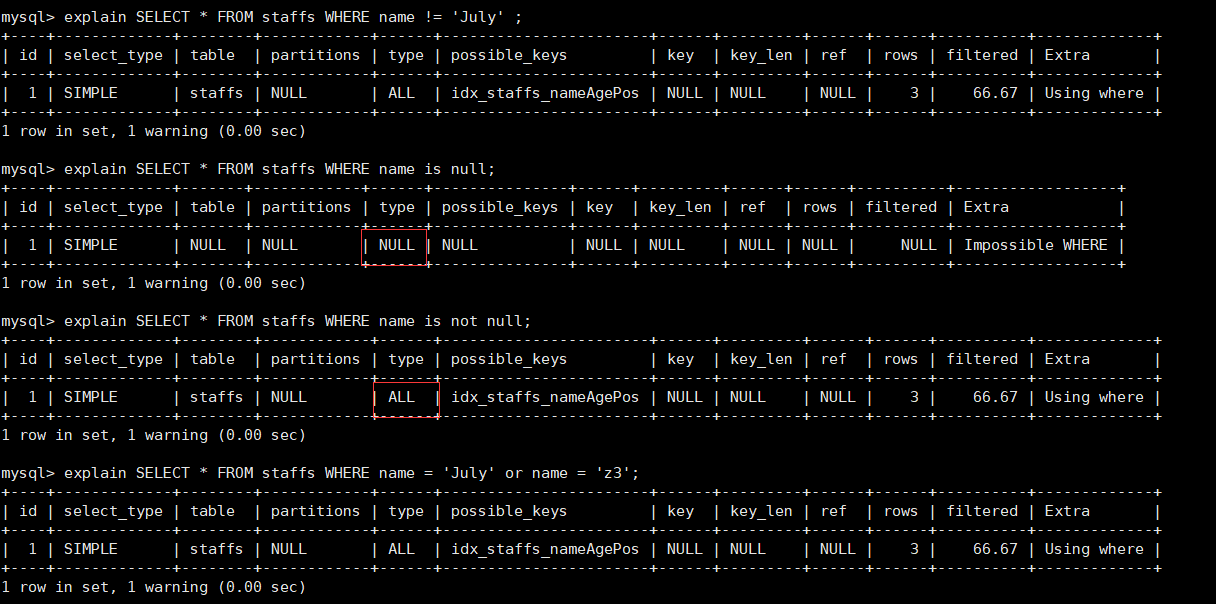
explain SELECT * FROM staffs WHERE name != 'July' ; explain SELECT * FROM staffs WHERE name is null; explain SELECT * FROM staffs WHERE name is not null; explain SELECT * FROM staffs WHERE name = 'July' or name = 'z3';
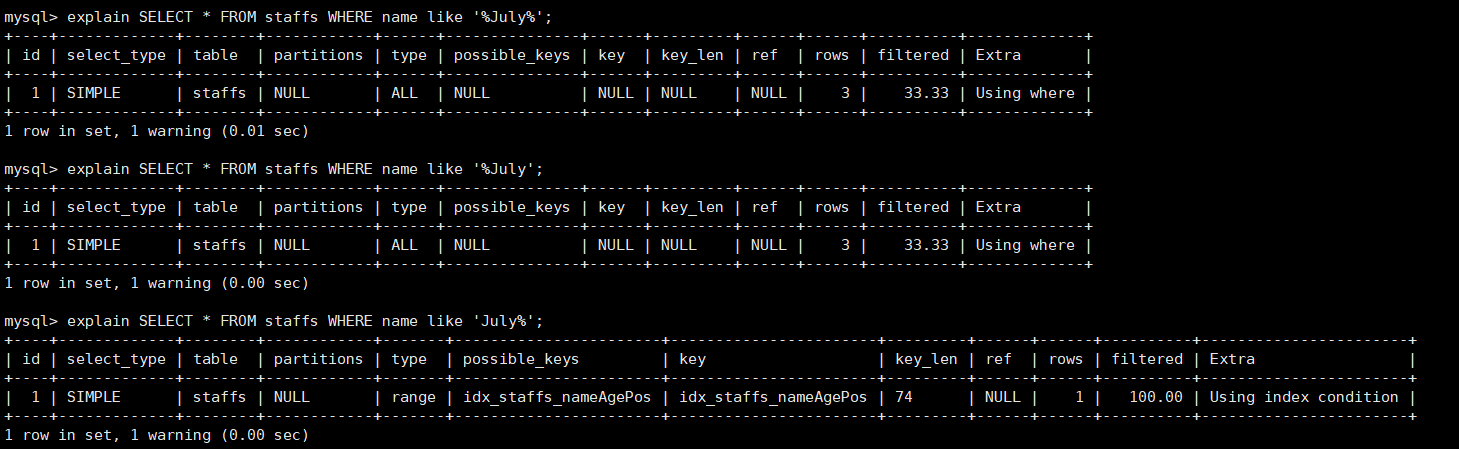
explain SELECT * FROM staffs WHERE name like '%July%'; explain SELECT * FROM staffs WHERE name like '%July'; explain SELECT * FROM staffs WHERE name like 'July%';
create table dept( id int unsigned primary key auto_increment, deptno mediumint unsigned not null default 0, dname varchar(20) not null default "", loc varchar(13) not null default "" )engine=innodb default charset=GBK;
CREATE TABLE emp( id int unsigned primary key auto_increment, empno mediumint unsigned not null default 0, ename varchar(20) not null default "", job varchar(9) not null default "", mgr mediumint unsigned not null default 0, hiredate date not null, sal decimal(7,2) not null, comm decimal(7,2) not null, deptno mediumint unsigned not null default 0 )ENGINE=INNODB DEFAULT CHARSET=GBK;
//函数 delimiter $$ create function ran_string(n int) returns varchar(255) begin declare chars_str varchar(100) default 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ'; declare return_str varchar(255) default ''; declare i int default 0; while i < n do set return_str = concat(return_str,substring(chars_str,floor(1+rand()*52),1)); set i=i+1; end while; return return_str; end $$ //函数 delimiter $$ create function rand_num() returns int(5) begin declare i int default 0; set i=floor(100+rand()*10); return i; end $$
//存储过程 delimiter $$ create procedure insert_emp(in start int(10),in max_num int(10)) begin declare i int default 0; set autocommit = 0; repeat set i = i+1; insert into emp(empno,ename,job,mgr,hiredate,sal,comm,deptno) values((start+i),ran_string(6),'salesman',0001,curdate(),2000,400,rand_num()); until i=max_num end repeat; commit; end $$ //存储过程 delimiter $$ create procedure insert_dept(in start int(10),in max_num int(10)) begin declare i int default 0; set autocommit = 0; repeat set i = i+1; insert into dept(deptno,dname,loc) values((start+i),ran_string(10),ran_string(8)); until i=max_num end repeat; commit; end $$
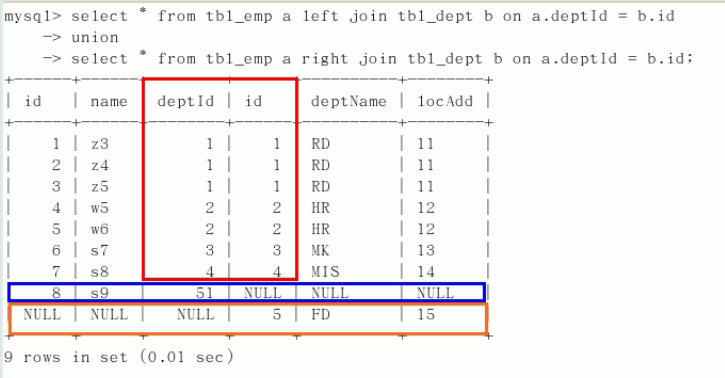
select * from t_emp; select * from t_emp e inner join t_dept d where e.id = d.id;
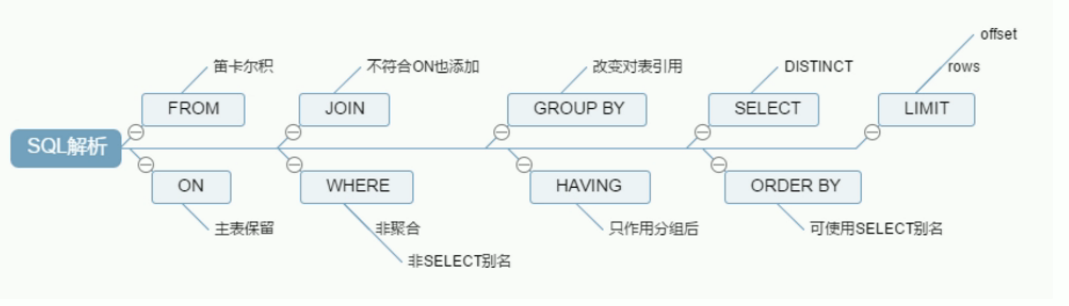
# 如下两句会报错,如果在 SELECT 中的列,没有在 GROUP BY 中出现,那么这个 SQL 是不合法的,因为列不在 GROUP BY 从句中 # 需要开启sql_mode语法规则校验的一些设置 ONLY_FULL_GROUP_BY select * from emp group by id%10 limit 150000; # order by 5是按照第五列字段排序 select * from emp group by id%20 order by 5; ....
sql_mode补充:
sql_mode 定义了对 Mysql 中 sql 语句语法的校验规则!
sql_mode 是个很容易被忽视的变量,默认值是空值,在这种设置下是可以允许一些非法操作的,比如允许一些非法数据的插入。在生产环境必须将这个值设置为严格模式,所以开发、测试环境的数据库也必须要设置,这样在开发测试阶段就可以发现问题。
1 2 3 4
mysql> select @@sql_mode\G *************************** 1. row *************************** @@sql_mode: ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION 1 row in set (0.00 sec)
查看当前的 sql_mode: select @@sql_mode;
临时修改 sql_mode: set @@sql_mode=’’;
永久修改,需要在配置文件 my.cnf 中修改:[mysqld] 下添加 sql_mode='' 然后重启 mysql 即可
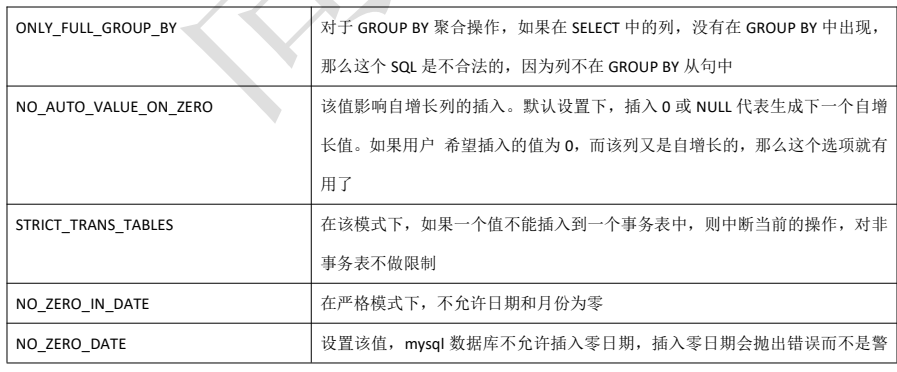
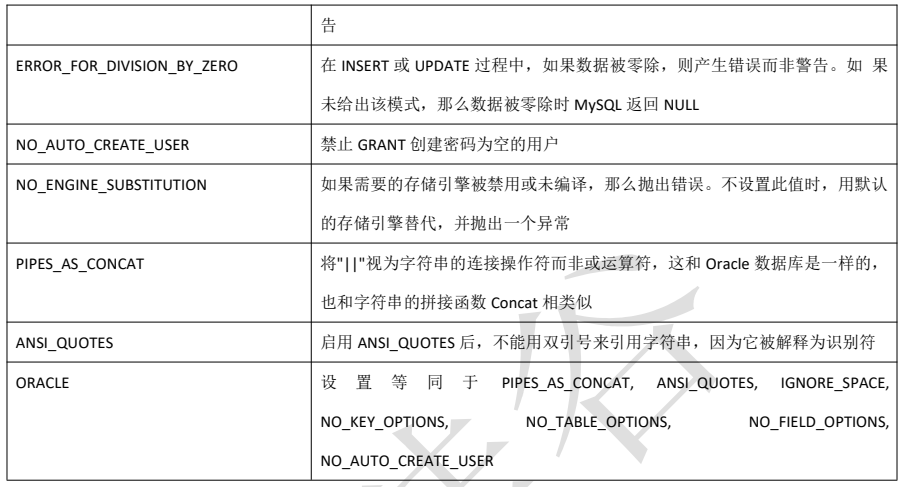
create table mylock ( id int not null primary key auto_increment, name varchar(20) default '' ) engine myisam;
insert into mylock(name) values('a'); insert into mylock(name) values('b'); insert into mylock(name) values('c'); insert into mylock(name) values('d'); insert into mylock(name) values('e');
CREATE TABLE test_innodb_lock (a INT(11),b VARCHAR(16))ENGINE=INNODB;
# 插入数据 INSERT INTO test_innodb_lock VALUES(1,'b2'); INSERT INTO test_innodb_lock VALUES(3,'3'); INSERT INTO test_innodb_lock VALUES(4, '4000'); INSERT INTO test_innodb_lock VALUES(5,'5000'); INSERT INTO test_innodb_lock VALUES(6, '6000'); INSERT INTO test_innodb_lock VALUES(7,'7000'); INSERT INTO test_innodb_lock VALUES(8, '8000'); INSERT INTO test_innodb_lock VALUES(9,'9000'); INSERT INTO test_innodb_lock VALUES(1,'b1');
# 创建索引 CREATE INDEX test_innodb_a_ind ON test_innodb_lock(a); CREATE INDEX test_innodb_lock_b_ind ON test_innodb_lock(b);
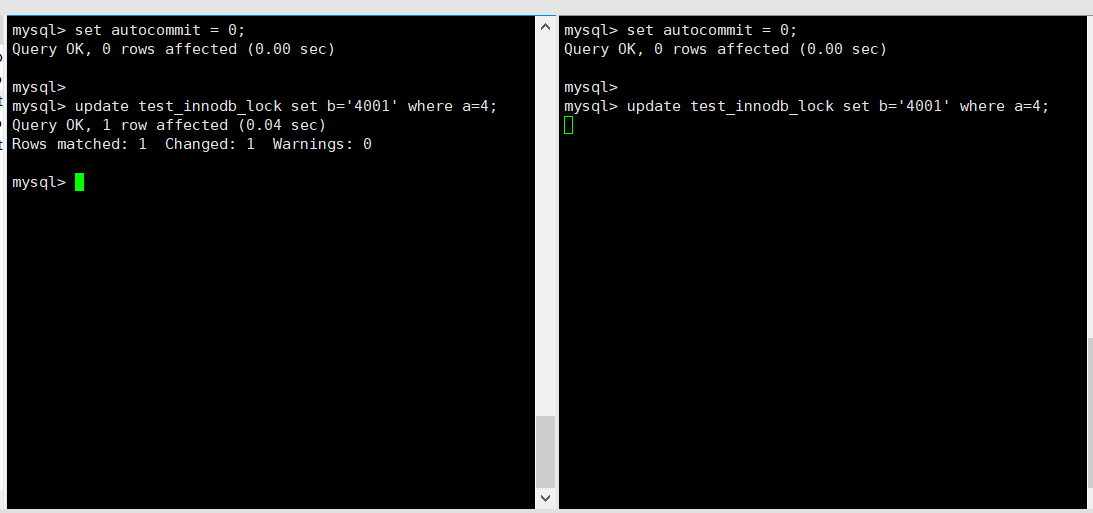
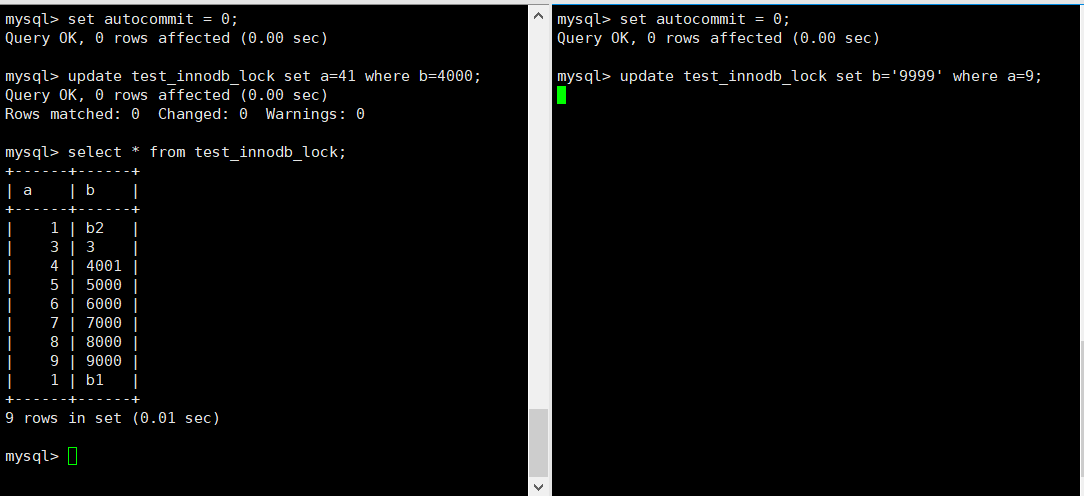
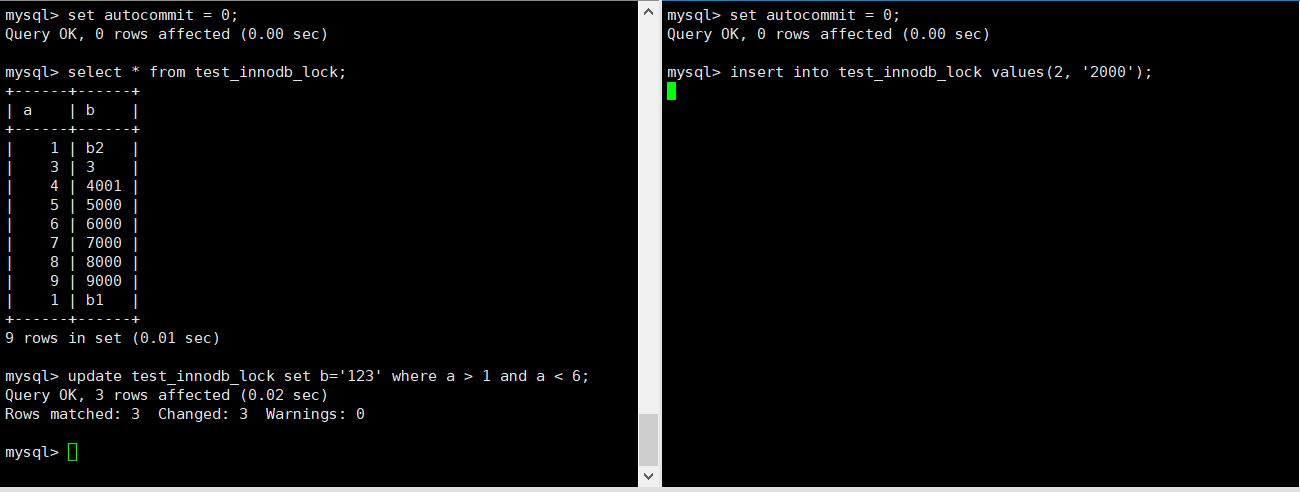
------------------------------------------------------------ # 关闭自动提交,不进行自动提交,相当于默认加了行锁! SET autocommit=0; ------------------------------------------------------------


































 微信
微信 支付宝
支付宝
