
再学MySql之使用大总结
¶一、DQL语言
DQL(Data Query Language):数据查询语言,用于查询!
¶1、基础查询
¶1.1、语法
- 查询列表可以是:表中的字段、常量值、表达式、函数
- 查询的结果是一个虚拟的表格
SELECT *代表查询该表全部字段- 查询字符型和日期型的常量值必须用单引号引起来,数值型不需要
1 | |
¶1.2、别名
1 | |
¶1.3、去重
1 | |
¶1.4、关于+号
仅有运算符的功能!
select 数值+数值:直接运算select 字符+数值:先试图将字符转换成数值,如果转换成功,则继续运算;否则转换成0,再做运算select null+值:结果都为null
¶1.5、几个函数
contact(xxx,xxx,xxx ...):字符串拼接ifnull(expr1, expr2):判断expr1是否为null,如果为null返回expr2,否则返回expr1isnull(xxx):判断该字段值是否为null,是返回1,否则返回0
¶2、条件查询
¶2.1、语法
1 | |
¶2.2、运算符
- 条件运算符:
>、<、=、!=、<>、>=、<= - 逻辑运算符:
and or not - 模糊查询关键字:
like:一般搭配通配符使用,可以判断字符型或数值型。- 通配符:
%任意多个字符,_任意单个字符 - 若匹配
_ 或 %则需要使用转移字符\,或使用escape自定义转义字符
- 通配符:
between xxx and xxx:在两范围之间,包含临界值in(xxx, xxx ...):in列表的值类型必须一致或兼容in列表中不支持通配符
is null:=或<>不能用于判断null值,is null或is not null可以判断null值is not null:略
- 安全等于
<=>:可以判断可判断null和普通数值型,由于长得模棱两可,可读性低,一般不用
1 | |
¶3、排序查询
¶3.1、语法
1 | |
¶3.2、注意点
-
asc代表的是升序,可以省略。desc代表的是降序 -
order by子句可以支持 单个字段、别名、表达式、函数、多个字段 -
order by子句在一般放在查询语句的最后面,除了limit子句
¶4、常见函数
sql语言中索引从1开始!
¶1、字符函数
concat(exp1, exp2, exp3 …): 字符串连接substr(str1, int): 截取从int位置开始之后str1剩余的所有字符(索引从1开始)substr(str1, int1, int2): 截取str1中从int1开始的int2个字符upper(str):变大写lower(str):变小写replace(str1, str2, str3):str1中的所有str2被替换成了str3length(str):获取字节长度(一个汉字是三个字节)trim(str): 去前后空格 (不光去空格 )SELECT TRIM('aa' FROM 'aaa哈哈哈aaa'):返回a哈哈哈a
lpad(str1, int, str2):左填充,结果的长度为int,str1长度若不够int,将str2填充到str1左侧,直到长度为 int,如果str1长度大于int,则从左往右取int个输出,int不是指字节,指字符rpad(str1, int, str2):右填充instr(str1, str2): 获取str1中第一次出现str2的索引值,如果找不到返回0
¶2、数学函数
ceil(x): 向上取整floor(x):向下取整round(x, [d]):四舍五入,d代表保留小数位数mod(n, m):取模truncate(x, d): 截断,将数值保留int位小数,剩余尾数截断rand(): 获取随机数,返回0-1之间的小数
¶3、日期函数
¶4、其他函数
version(): 当前数据库服务器的版本database(): 当前打开的数据库user(): 当前用户password('字符’):返回该字符的密码形式,新版mysql已不支持`md5(‘字符’): 返回该字符的md5加密形式
¶5、流程控制函数
if(条件表达式,表达式1,表达式2):类似三元运算符- 可以作为表达式放在任何位置
case情况1:类似于switch case,else省略,若都不匹配,则返回null- 可以放在任何位置:
- 如果放在begin end 外面,作为表达式结合着其他语句使用
- 如果放在begin end 里面,一般作为独立的语句使用
- 可以放在任何位置:
1 | |
case情况2:类似于if else
1 | |
例如:
1 | |
¶6、分组函数
又叫做:聚合函数,统计函数,组函数
主要有:
sum avg max min count
参数类型:
sum, avg:适用于数值型,字符型也不报错,返回0max, min:数值型,字符型count:不为null的个数
**注意:**以上分组函数都忽略null值
- 可以和
distinct搭配实现去重,eg:SELECT SUM(DISTINCT salary) FROM employees; - 和分组函数一同查询的字段要求是
group by后的字段,其他不行 count(*):不忽略null,即返回总行数!- 如下写法,相当于加了一列:
1 | |
效率:
myisam引擎:count(*)效率最高innodb引擎:count(*)和count(1)差不多,比count(字段)高
¶5、分组查询
¶5.1、语法
注意:查询的列表比较特殊,要求是分组函数和group by后出现的字段
1 | |
举例:
1 | |
¶5.2、having & where
-
where:对分组前结果进行筛选,放在group by之前 -
having:对分组后的结果进行筛选,放在group by之后,聚集函数一般放在having后!
¶6、连接查询
又称为多表查询!防止未添加连接条件导致产生笛卡尔积现象!
为方便操作,一般为表起别名!
注意:为表起了别名,则查询的字段将不能再使用原表名进行限定,只能使用别名
¶6.1、分类
mysql虽然不支持全外连接,但可以使用UNION,左连接一次,右连接一次,再使用UNION合并来实现全外连接!
- 年代分类
sql92:仅仅支持内连接(where后添加连接条件,已被弃用)sql99:全支持,但mysql不支持全连接!(on后添加连接条件)
- 功能分类
- 内连接(等值连接(交集)、非等值连接、自连接)
- 外连接(左外、右外、全外(
mysql不支持)) - 交叉连接
¶6.2、sql99语法
1、内连接
1 | |
2、左外&右外连接
left join左边的就是主表,right join右边的就是主表,full join两边都是主表!
1 | |
3、交叉连接
类似笛卡尔积!
1 | |
¶6.3、总结
- 内连接和左右外连接
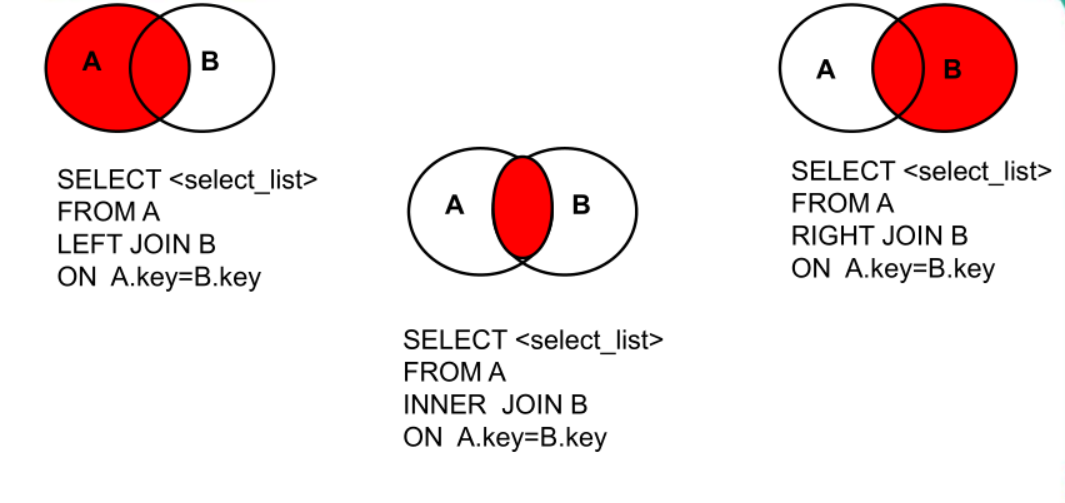
- 其他几种
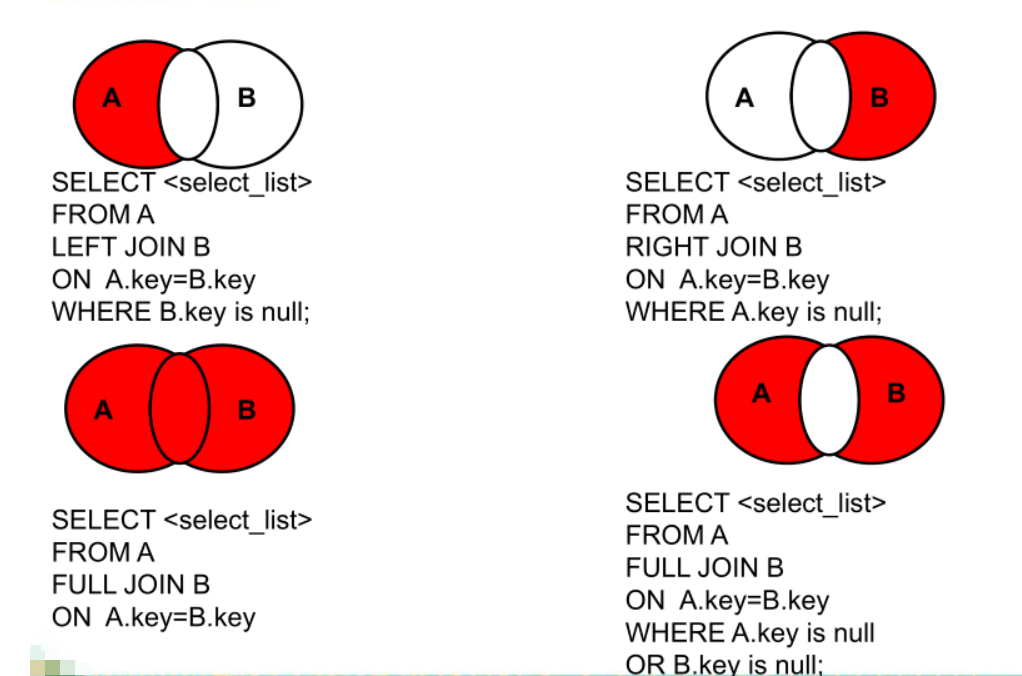
¶7、子查询
可由后面的视图代替,提高可读性!
嵌套在其他语句内部的
select语句称为子查询或内查询,外面如果为select语句,则此语句称为外查询或主查询!外面的语句可以是
insert、update、delete、select等,一般select作为外面语句较多!
¶7.1、分类
- 按出现位置
select后面:支持标量子查询from后面:支持表子查询(子查询结果为一张虚拟表,要求必须起别名)where或having后面:支持标量子查询、列子查询 、行子查询exists后面(相关子查询):标量子查询、列子查询、行子查询、表子查询
- 按结果集行列
- 标量子查询(单行子查询):结果集为一行一列
- 列子查询(多行子查询):结果集为多行一列
- 行子查询:结果集为多行多列
- 表子查询:结果集为多行多列
exists(完整的查询语句):结果为1或0,可用in代替!
举例:
1 | |
¶7.2、注意点
- 子查询放在小括号内
- 子查询一般放在条件的右侧
- 子查询的执行优先于主查询,主查询用到了子查询的结果
- 标量子查询,一般搭配单行操作符使用
< > >= <= - <> - 列子查询:一般搭配多行操作符使用
in \ not in \ any/some \ allin等于其中一个即可not in不是其中每个any/some比较其中一个即可 (可替换为max,min)all比较所有值 (可替换为max,min)
列子查询举例:
1 | |
¶8、分页查询
¶8.1、语法
-
offset:起始索引(起始索引从0开始,唯一一个从0开始的,其他都是1开始) -
size:显示条数
1 | |
¶8.2、注意点
-
limit语句放在查询语句的最后 -
要显示的页数
page,每页的条目数size,limit (page-1)*size, size; -
使用
order by和limit组合,可以找到一个列中最大值、最小值
¶9、联合查询
多次查询合并!
将一条比较复杂的查询语句拆分成多条语句!
¶9.1、语法
1 | |
¶9.2、注意点
- 要求多条查询语句的查询列数必须一致
- 要求多条查询语句的查询的各列类型、顺序最好一致
union去重,union all包含重复项
¶10、查询总结
各大关键字的位置及其执行顺序!
1 | |
¶二、DML语言
DML(Data Manipulation Language):数据操纵语言,负责对数据库对象运行数据访问工作的指令集,以
INSERT、UPDATE、DELETE三种指令为核心!
¶1、插入
¶1.1、语法
1 | |
¶1.2、区别和注意点
- 方式一只需保证对应一致即可
- 方式一支持插入多行,方式二不支持
- 方式一支持子查询,方式二不支持
- 不可以为
null的列必须插入值,可以为null的列可以写或不写 - 省略列名,默认所有列,值和表列的顺序要一致。
1 | |
¶2、修改
¶1.1、语法
1 | |
¶3、删除
可以使用
delete和truncate!
¶3.1、语法
1 | |
1 | |
¶3.2、delete & truncate
-
delete可以加where条件,truncate不能加 -
truncate删除,效率高一丢丢 -
假如要删除的表中有自增长列,如果用
delete删除后,再插入数据,自增长列的值从断点开始;而truncate删除后,再插入数据,自增长列的值从1开始。 -
truncate删除没有返回值,delete删除有返回值 -
truncate删除不能回滚,delete删除可以回滚.
¶三、DDL语言
DDL(Data Definition Language):数据定义语言,处理库和表的管理及各种约束!以
create、alter、drop三种指令为核心!
¶1、库的管理
¶1.1、创建库
1 | |
¶1.2、修改库
1 | |
¶1.3、删除库
1 | |
¶2、表的管理
¶2.1、创建表
1 | |
¶2.2、修改表
1 | |
¶2.3、删除表
1 | |
¶2.4、复制表
1、复制表的结构
1 | |
2、复制表的结构以及数据
1 | |
¶3、数据类型
¶3.1、分类
- 整型型:
tinyint(1)、smallint(2)、mediumint(3)、int/integer(4)、bigint(8)- 如果不设置无符号还是有符号,默认是有符号,如果想设置无符号,需要添加
unsigned关键字 - 如果插入的数值超出了整型的范围,会报
out of range异常,并且插入临界值 - 如果不设置长度,会有默认的长度长度代表了显示的最大宽度,如果不够会用0在左边填充,但必须搭配
zerofill使用!
- 如果不设置无符号还是有符号,默认是有符号,如果想设置无符号,需要添加
- 小数型:
float(M,D)浮点型 :4字节,double(M,D)定点型: 8字节M代表整数部位+小数部位的字符个数,D代表小数部位- 如果超出范围,则报
out or range异常,并且插入临界值 M和D都可以省略,但对于定点数,M默认为10,D默认为0- 如果精度要求较高,则优先考虑使用定点数
- 字符型:
char、varchar、binary(二进制)、varbinary(二进制)、enum(枚举)、set(集合)、text、blob(较大二进制)char:固定长度的字符,写法为char(M),最大长度不能超过M,其中M可以省略,默认为1varchar:可变长度的字符,写法为varchar(M),最大长度不能超过M,其中M不可以省略
- 日期型:
date、time、year、datetime(8字节,范围:1000—9999)、timestamp(4字节,范围:1970-2038)timestamp:比较容易受时区、语法模式、版本的影响,更能反映当前时区的真实时间SET time_zone='+9:00':可设置时区
小栗子:
1 | |
¶4、常见约束
¶4.1、常见约束
NOT NULL:非空,该字段的值必填UNIQUE:唯一,该字段的值不可重复DEFAULT:默认,该字段的值不用手动插入有默认值CHECK:检查,mysql不支持PRIMARY KEY:主键,该字段的值不可重复并且非空 ,等同于unique + not nullFOREIGN KEY:外键,该字段的值引用了另外的表的字段
¶4.2、主键 & 唯一键
- 一个表至多有一个主键,但可以有多个唯一
- 主键不允许为空,唯一可以为空
- 注意:新版支持唯一多
null - 联合主键:
PRIMARY KEY(xxx, xxx),索引会显示两个主键(二者为整体来决定) - 联合唯一键:
UNIQUE(seat, age),类似!
¶4.2、外键
外键写法:
[constraint 约束名] foreign key(从表被约束的列) references 主表(主表被引用列)
- 用于限制两个表的关系,从表的字段值引用了主表的某字段值
- 外键列和主表的被引用列要求类型一致,意义一样,名称无要求
- 主表的被引用列要求是一个key(一般是主键或唯一键)
- 插入数据,先插入主表。删除数据,先删除从表
可以通过以下两种方式来删除主表的记录:
1、级联删除:删除主表该数据的同时将从表该数据也删除
注意:接下来使用delete删除时,主表删除谁则从表对应数据行也删除
1 | |
2、级联置空:删除主表该数据的同时将从表该数据也置空
注意:接下来使用delete删除时,主表删除谁则从表对应数据(使用主表外键的列)置空
1 | |
¶4.3、约束使用
1、创建表时添加约束
列级约束:不可以设置约束名
- 只支持默认、非空、主键、唯一键
- 一个字段可写多个,顺序随意,空格隔开即可
表级约束:
【constraint 约束名】 约束类型(字段名)
只支持主键、外键、唯一键
可选部分不写默认为字段名!
对主键无效!
注意:主键、外键、唯一键会自动生成索引。可使用
SHOW INDEX FROM 表名查看索引!
1 | |
2、修改表时添加或删除约束
2.1、非空
1 | |
2.2、默认
1 | |
2.3、主键
1 | |
2.4、唯一
1 | |
2.5、外键
1 | |
3、通用或建议写法
1 | |
¶4.4、自增长列
不用手动插入值,可以自动提供序列值,默认从1开始,步长为1!
1、注意点
- 一个表至多有一个自增长列
- 自增长列只能支持数值型
- 自增长列必须为一个
key(主键、唯一键、外键)
2、更改默认起始值和步长
对于更改起始值:也可以在第一次插入时指定该值,则之后自增就以该值开始!
注意:使用
set设置变量,影响范围为当前会话,可以添加global|session修改为所有会话,永久改变,只能修改配置文件!
1 | |
3、创建表时设置自增长列
自增长列赋值可以为
null,还是自增!也可在插入时不插入该列!
1 | |
4、修改表时设置自增长列
1 | |
5、删除自增长列
1 | |
¶4.5、索引
¶四、DCL语言
DCL(Data Control Language):数据控制语句,用于控制不同数据段直接的许可和访问级别的语句。这些语句定义了数据库、表、字段、用户的访问权限和安全级别。主要的语句关键字包括
grant、revoke等。
¶五、TCL语言
TCP(Transaction Control Language):事务控制语言,处理事务及使用隔离级别解决并发问题!
¶1、事务
事务:一条或多条
sql语句组成一个执行单位,一组sql语句要么都执行要么都不执行,把多条语句作为一个整体进行操作的功能,被称为数据库事务!
¶1.1、事务的ACID四个特性
A:Atomic,原子性,将所有SQL作为原子工作单元执行,要么全部执行,要么全部不执行;
C:Consistent,一致性,事务完成后,所有数据的状态都是一致的,即A账户只要减去了100,B账户则必定加上了100;
I:Isolation,隔离性,如果有多个事务并发执行,每个事务作出的修改必须与其他事务隔离;
D:Duration,持久性,即事务完成后,对数据库数据的修改被持久化存储。
¶1.2、事务的创建
-
隐式事务:事务没有明显的开启和结束的标记
-
显示事务:事务具有明显的开启和结束的标记,前提:必须先设置自动提交功能为禁用
1 | |
¶1.3、使用保留点savepoint
1 | |
¶2、隔离级别
我之前写的教程更加详细:隔离级别,点击这里!
¶2.1、注意点
-
serializable:效率低,类似于java多线程的锁,同一时刻只能有一个事务操作 -
oracle支持两种:serializable \ read committed
¶2.2、默认隔离级别
mysql(如果使用InnoDB)中默认 第三个隔离级别repeatable readoracle中默认第二个隔离级别read committed
¶2.3、查看隔离级别
1 | |
¶2.4、设置隔离级别
1 | |
在变量章节详细讲解!
session:当前事务(可选,不写则不会马上生效)global:全局,一般设置后需重启mysql
¶六、视图
mysql5.1版本出现的新特性,本身是一个虚拟表,它的数据来自于表,通过执行时动态生成。只保存了sql逻辑,不保存查询结果!
- 简化
sql语句,提高了sql的重用性- 保护基表的数据,提高了安全性(即封装性,将子查询封装)
¶1、视图和表对比
- 表保存数据,视图仅保存逻辑语句
- 视图一般用于查询,表一般用于增删改查
¶2、创建视图
使用:可以将视图名称当做表名使用即可!
1 | |
¶3、修改视图
1 | |
¶4、删除视图
1 | |
¶5、查看视图
1 | |
¶6、更新视图
和表的操作一致,
insert, update, delete!
以下视图不允许更新:
- 包含以下关键字的
sql语句:分组函数、distinct、group by、having、union或者union all join- 常量视图
where后的子查询用到了from中的表- 用到了不可更新的视图
¶七、变量
global:所有会话(当前mysql所有连接,重启失效)
session:默认值,当前会话永久生效:修改配置文件
¶1、系统变量
分类:
- 全局变量
- 会话变量
¶1.1、查看所有系统变量
1 | |
¶1.2、查看满足条件的部分系统变量
1 | |
¶1.3、查看指定的系统变量的值
1 | |
¶1.4、为某个系统变量赋值
1 | |
¶2、自定义变量
分类:
- 用户变量
- 局部变量
¶2.1、用户变量
作用域:针对于当前连接(会话)生效
位置:
begin end里面,也可以放在外面注意:一般添加
@
1 | |
¶2.2、局部变量
作用域:仅仅在定义它的
begin end中有效位置:只能放在
begin end中,而且只能放在第一句注意:一般不添加
@
1 | |
¶八、存储过程和函数
类似于方法!
¶1、存储过程
视图是逻辑语句,存储过程是执行完的集合!一组预先编译好的SQL语句的集合,理解成批处理语句!
存储过程无法被修改,只可以删除之后重建!
¶1.1、创建
- 如果存储过程体仅仅只有一句话,
begin end可以省略。- 存储过程体中的每条
sql语句的结尾要求必须加分号。- 需要使用分隔符结束!
1 | |
参数模式:
in:该参数需要调用方传入值(默认,可省略,但不建议)out:该参数可以作为返回值inout:该参数既需要传入值,又可以返回值
几个例子:
1 | |
¶1.2、分隔符
防止遇到分号提前结束语句!
结束标记一旦指定,则当前会话结束标记都应为该符号!
sqlyog有点bug,每次运行都必须得指定该分隔符,控制台没问题!
1 | |
¶1.3、调用
1 | |
¶1.4、查看
1 | |
¶1.5、删除
1 | |
¶2、函数
¶2.1、函数与存储过程区别
- 存储过程:可以有0个返回,也可以有多个返回,适合做批量插入、批量更新
- 函数:有且仅有1个返回,适合做处理数据后返回一个结果
¶2.2、创建
- 函数体中仅有一句话,则可以省略
begin end- 使用
delimiter语句设置结束标记
1 | |
几个例子:
1 | |
¶2.3、调用
1 | |
¶2.4、查看
1 | |
¶2.5、删除
1 | |
¶九、流程控制结构
¶1、分支结构
if函数和case结构看第一章的第四节的第五小结的流程控制函数!
¶1.1、if结构
只能放在
begin end中!
1 | |
例子:
1 | |
¶2、循环结构
位置:都只能放在
begin end中
¶2.1、while
1 | |
¶2.2、loop
类似死循环!
1 | |
¶2.3、repeat
类似
do while!
1 | |
¶2.4、循环控制语句
leave:类似于break,用于跳出所在的循环iterate:类似于continue,用于结束本次循环,继续下一次
几个例子:
1 | |
¶十、游标和触发器
 微信
微信 支付宝
支付宝

