
MySQL数据库索引、索引失效、B树、B+树、聚簇索引、非聚簇索引
¶一、索引数据结构介绍
都以插入1-10这10个数字为例!
¶1、哈希索引
可视化哈希索引,https://www.cs.usfca.edu/~galles/visualization/ClosedHash.html
可以发现查找可以直接找到,因为是计算了哈希值,可以直接找到!效率非常高!
但是,为什么MySQL没有使用这种数据结构了?
- 哈希值是无序的,不能进行范围查找
- 不能进行排序
- 哈希冲突,比对,可能发生全表扫描
¶2、平衡二叉树
可视化平衡二叉树,https://www.cs.usfca.edu/~galles/visualization/AVLtree.html
查找10的过程: 也仅仅比了四次!
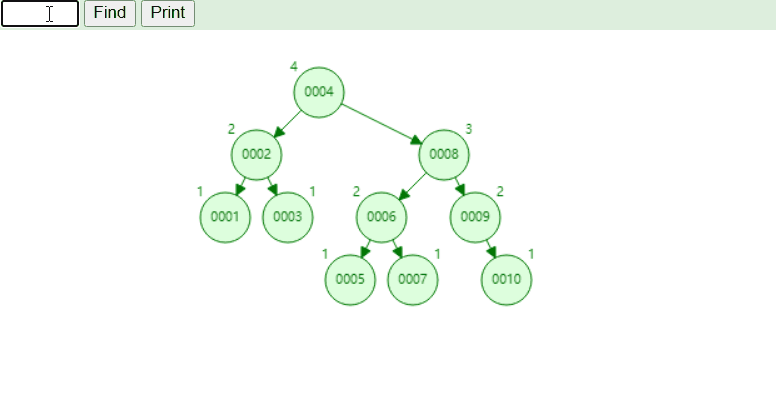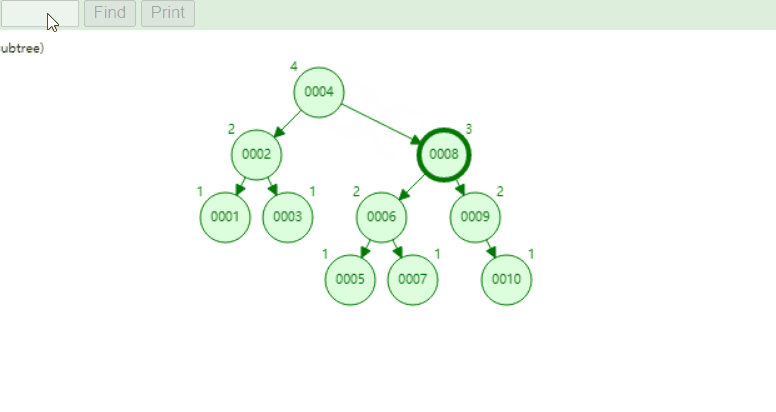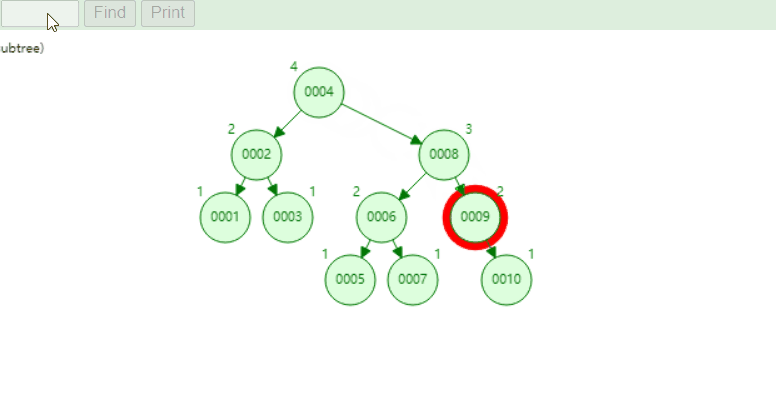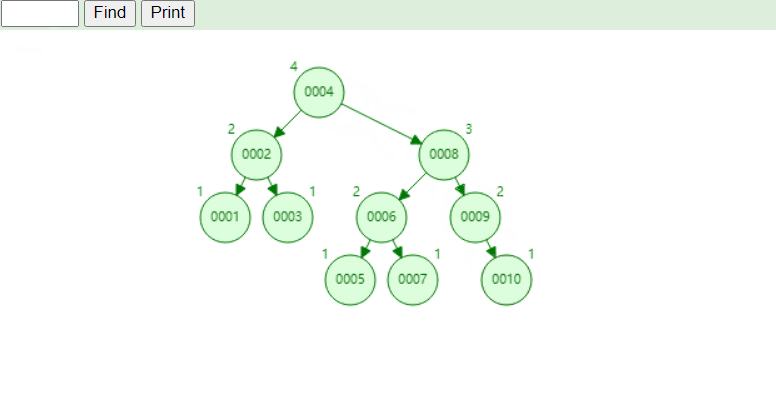
缺点:
- 随着数据量的增大,树的高度也会增加,查找速度会越来越慢
- 还有一个致命缺点,若查找大于5的范围,他将会先找到5再进行回旋查找大于5的数,若大于5的数非常多,将会导致非常的慢
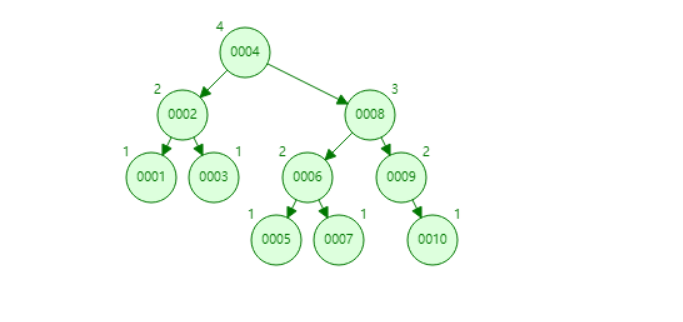
¶3、B树
可视化B树,https://www.cs.usfca.edu/~galles/visualization/BTree.html
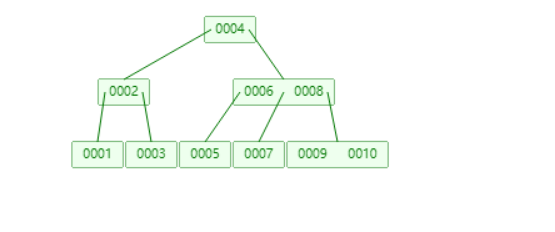
优点:由于一个节点存储的大于一个值,因此树高会变矮,变矮就表示查询次数会少很多!
缺点:
同样存在回旋查找的问题,查找大于5仍然会进行回旋查找浪费时间!
¶4、B+树
可视化B+树,https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html
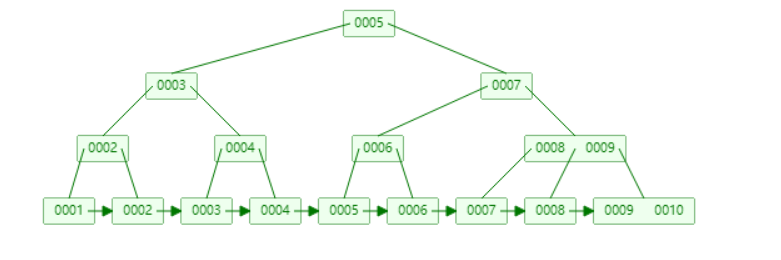
与B树不同,他的非叶子节点只存储key,不存储value。叶子节点存储key和value!
这里的value指的是内存地址!
注意:这里的1和10兼具叶子节点和非叶子节点特点,成为了二者共用,
且叶子节点都以链表形式相连!且有序!
优点:解决了上面的回旋查找的问题!
¶二、索引失效分析
联合索引B+树结构!
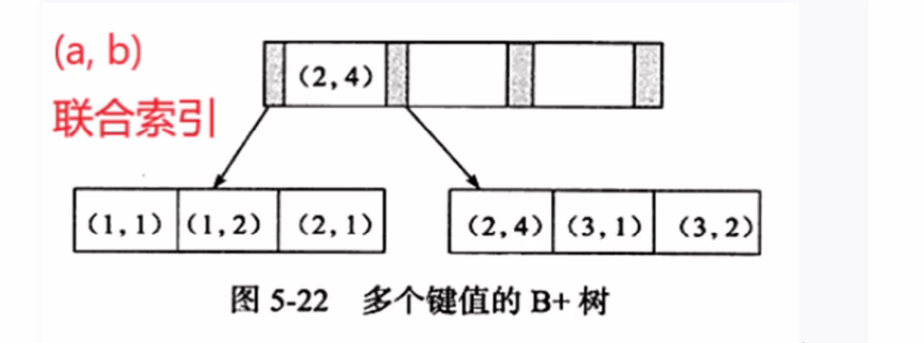
¶1、联合索引
从上图来看,会发现该数据结构的特点:
- 联合索引是按照顺序一个个排序的,即a有序,在a有序的情况下b有序
¶2、索引失效分析
- 最佳左前缀原因:因为它是索引顺序一个个排序的,若前面某个索引列没有使用到,那么对于B+数的叶子节点来说,叶子节点就完全是无序的,因此索引就完全失效了,只能进行全表扫描!
- 范围之后全失效:例如找a>1的数据,会发现a>1的数据中b是无序的,因此索引失效,只能进行全表扫描。因为只有a相同的情况下b才是有序的!否则无序!
- like的%号左边、两边索引失效:和最佳左前缀法则一样,也是从左到右进行排序的,放左边和两边会导致之前的无法先排序之前的,导致后面的数据全部无序,只能进行全表扫描!
注意:这里的无序不仅仅指B+树的叶子节点无序,非叶子节点同样是无序的!
¶三、MyIsam和InnoDB常见区别
¶事务方面
InnoDB 支持事务,MyISAM 不支持事务。这是 MySQL 将默认存储引擎从 MyISAM 变成 InnoDB 的重要原因之一。
¶外键方面
InnoDB 支持外键,而 MyISAM 不支持。对一个包含外键的 InnoDB 表转为 MYISAM 会失败。
¶索引层面
InnoDB 是聚集(聚簇)索引,MyISAM 是非聚集(非聚簇)索引。
MyISAM支持 FULLTEXT类型的全文索引, InnoDB不支持FULLTEXT类型的全文索引,但是InnoDB可以使用sphinx插件支持全文索引,并且效果更好。
¶锁粒度方面
InnoDB 最小的锁粒度是行锁,MyISAM 最小的锁粒度是表锁。
一个更新语句会锁住整张表,导致其他查询和更新都会被阻塞,因此并发访问受限。
这也是 MySQL 将默认存储引擎从 MyISAM 变成 InnoDB 的重要原因之一。
¶硬盘存储结构
MyISAM在磁盘上存储成三个文件。第一个文件的名字以表的名字开始,扩展名指出文件类型。
.frm文件存储表的定义。数据文件的扩 展名为.MYD(MYData)。索引文件的扩 展名是.MYI(MYIndex)。
Innodb存储引擎存储数据库数据,一共有两个文件(没有专门保存数据的文件):
Frm文件:表的定义文件。Ibd文件:数据和索引存储文件。数据以主键进行聚集存储,把真正的数据保存在叶子节点中。
¶四、聚簇索引和非聚簇索引
¶聚簇索引(InnoDB)
将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据。
表数据按照索引的顺序来存储的,也就是说索引项的顺序与表中记录的物理顺序一致。
InnoDB中,在聚簇索引之上创建的索引称之为辅助索引,像复合索引、前缀索引、唯一索引等等。
- 聚簇索引默认是主键
- 如果表中没有定义主键,InnoDB 会选择一个
唯一的非空索引代替。 - 如果没有这样的索引,InnoDB 会在内部生成一个名为
GEN_CLUST_INDEX的隐式的聚簇索引。
¶非聚簇索引(MyISAM)
将数据与索引分开存储,表数据存储顺序与索引顺序无关。
¶图解两大索引
非聚簇索引存储结构:
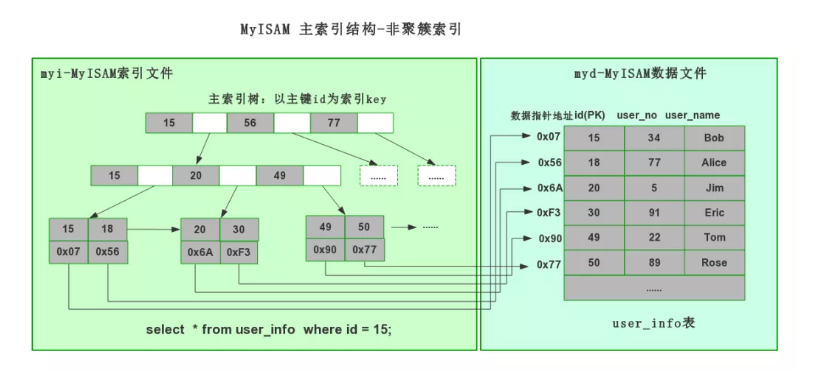
MyISAM的 B+树 的叶子节点上,记录的是真实数据的存储地址。
比如通过主键id查询,MyISAM查询流程如下:
- 根据id值在B+树上找到相应的叶子节点
- 取出叶子节点上的数据存储地址
- 根据数据存储地址,去找到相应的真实数据
聚簇索引存储结构:
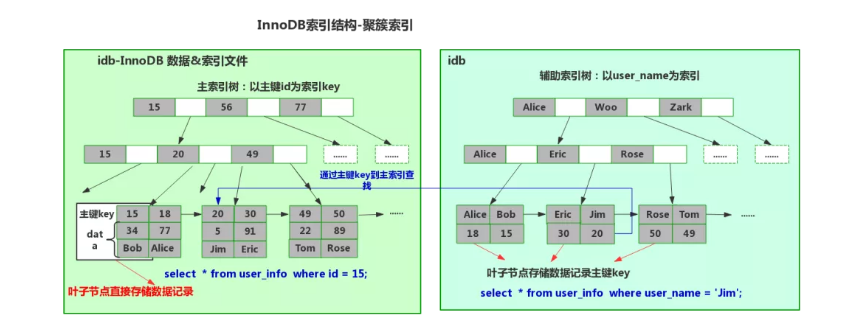
InnoDB的 B+树 的叶子节点上,记录的是真实行数据。
比如通过主键id查询,InnoDB查询流程如下:
聚簇索引(主键索引):
- 根据id值在B+树上找到相应的叶子节点
- 取出叶子节点上的行数据,返回即可
辅助索引(聚簇索引以外的):
- 在相应索引的B+树上找到相应的叶子节点
- 取出叶子节点上的数据,该数据是主键id
- 拿到主键id后,去主键索引的B+树上找到相应的叶子节点
- 取出叶子节点上的行数据,返回
¶思考?
为什么少用select *,为什么尽量使用覆盖索引?
- 对innodb的聚簇索引来说,如果查的是id,where条件是索引,那么可以查找一次B+树即可找到(辅助索引树)!
- 如果查找的是age字段,这个不是索引,那么我们得通过辅助索引树和主索引树才能找到!
- 这就是为什么尽量走覆盖索引和少用
select *的原因所在! - 当然真实场景不可能都走覆盖索引!
¶总结
- 通过主键id查询的时候,InnoDB比MyIsam快一些,因为InnoDB只需要一次B+树查找就能取出数据。MyIsam通过B+树查找到地址后,还需要根据地址去查询真正的数据。
- 但是InnoDB普通索引查询会比MyIsam慢些,因为InnoDB要进行2次B+树的查找。
- 在数据重构的时候,MyIsam记录的是数据地址,那么重构数据的时候地址就要重新生成一遍,这也是有问题的。
- InnoDB重构数据的时候就不会这样,因为他记录的是主键id,地址会变化,主键id是不会变的。
 微信
微信 支付宝
支付宝