
再学Java之StringBuffer、StringBuilder、枚举类、注解、集合和泛型
¶一、StringBuffer VS StringBuilder
¶1、String、StringBuffer、StringBuilder三者的对比
-
`String`:不可变的字符序列,底层使用`char[]`存储。 -
`StringBuffer`:可变的字符序列,**线程安全的,效率低**。底层使用`char[]`存储。 -
`StringBuilder`:可变的字符序列,**JDK5.0**新增的,**线程不安全的,效率高**。底层使用`char[]`存储。
因此,他们的效率高低依次为:StringBuilder > StringBuffer > String
注意: JDK8之后的版本使用的是byte[]存储!
¶2、使用建议
只要不是多线程问题,操作共享数据,都使用新增的StringBuilder!
¶3、StringBuffer、StringBuilder内存解析
二者在内存层面存储扩容方面几乎一致,这里以
StringBuffer为例!
¶3.1、先来看一下String的存储
String底层使用private final存储!
1 | |
¶3.2、StringBuffer
- 默认开辟长度为16的数组
- 若为有参构造器,则开辟参数的长度 + 16的数组
- 扩容问题:如果要添加的数据底层数组盛不下了,那就需要扩容底层的数组。默认情况下,扩容为原来容量的2倍 + 2,同时将原数组中的元素复制到新的数组中。
1 | |
¶3.3、总结
开发中建议大家使用:StringBuffer(int capacity) 或 StringBuilder(int capacity),提高效率!
¶二、枚举类
JDK5.0之前,自定义枚举类,JDK5.0之后,使用enum关键字!
¶1、自定义枚举类
1 | |
¶2、使用enum关键字
enum类的主要方法:values()方法:返回枚举类型的对象数组。该方法可以很方便地遍历所有的枚举值。valueOf(String str):可以把一个字符串转为对应的枚举类对象。要求字符- 串必须是枚举类对象的
名字。如不是,会有运行时异常:IllegalArgumentException。 toString():返回当前枚举类对象常量的名称
代码示例:
1 | |
- 使用
enum定义枚举类之后,如何让枚举类对象分别实现接口:- 实现接口,在枚举类中实现抽象方法
- 让枚举类对象分别实现接口中的抽象方法
代码示例:
1 | |
¶三、注解
JDK5.0 新增的功能!
框架 = 注解 + 反射机制 + 设计模式
¶1、注解概述
Annotation其实就是代码里的特殊标记, 这些标记可以在编译, 类加载, 运行时被读取, 并执行相应的处理。通过使用Annotation, 程序员可以在不改变原逻辑的情况下, 在源文件中嵌入一些补充信息。- 在
JavaSE中,注解的使用目的比较简单,例如标记过时的功能,忽略警告等。在JavaEE/Android中注解占据了更重要的角色,例如用来配置应用程序的任何切面,代替JavaEE旧版中所遗留的繁冗代码和XML配置等。
¶2、注解的作用
-
生成文档相关的注解
-
在编译时进行格式检查(JDK内置的几个基本注解)
@Override: 限定重写父类方法, 该注解只能用于方法@Deprecated: 用于表示所修饰的元素(类, 方法等)已过时。通常是因为所修饰的结构危险或存在更好的选择@SuppressWarnings: 抑制编译器警告
-
跟踪代码依赖性,实现替代配置文件功能
1 | |
¶3、自定义注解
参照
@SuppressWarnings定义!
-
注解声明为:
@interface -
内部定义成员,通常使用
value表示 -
可以指定成员的默认值,使用
default定义 -
如果自定义注解没成员,表明是一个标识作用。
说明:
- 如果注解有成员,在使用注解时,需要指明成员的值。
- 自定义注解必须配上注解的信息处理流程(使用反射)才意义。
- 自定义注解通常都会指明两个元注解:
Retention、Target
1 | |
¶4、JDK中的四种元注解
对现有的注解进行解释说明的注解!
后两种不常用。前两种常用,一般自定义注解都要有后两种!
Retention:指定所修饰的Annotation的生命周期:SOURCE\CLASS(默认行为)\RUNTIME,只有声明为RUNTIME生命周期的注解,才能通过反射获取。RetentionPolicy.SOURCE:在源文件中有效(即源文件保留),编译器直接丢弃这种策略的注解RetentionPolicy.CLASS:在class文件中有效(即class保留) ,当运行Java程序时,JVM不会保留注解。 这是默认值RetentionPolicy.RUNTIME:在运行时有效(即运行时保留),当运行Java程序时,JVM会保留注解。程序可以通过反射获取该注解
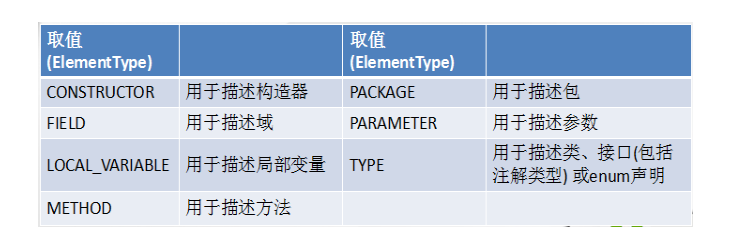
Target:用于指定被修饰的Annotation能用于修饰哪些程序元素Documented:表示所修饰的注解在被javadoc解析时,保留下来。Inherited:被它修饰的Annotation将具继承性。(解释:即父类使用了带有Inherited的注解,子类自动具有该注解)
Target注解的课取值:
¶5、JDK8中的新注解
¶5.1、可重复注解@Repeatable
- 在
MyAnnotation上声明@Repeatable,成员值为MyAnnotations.class MyAnnotation的Target和Retention等元注解与MyAnnotations相同。
1 | |
¶5.2、类型注解
在target的属性中加入该类型即可!
ElementType.TYPE_PARAMETER:表示该注解能写在类型变量的声明语句中,如:泛型声明ElementType.TYPE_USE:表示该注解能写在使用类型的任何语句中。
1 | |
¶四、集合
集合概述:
- Collection:单列集合
- List:存储序的、可重复的数据(JDK1.2)
- ArrayList:线程不安全的,效率高,底层使用
Object[] elementData存储。(JDK1.2)- LinkedList:对于频繁的插入、删除操作,使用此类效率比
ArrayList高,底层使用双向链表存储。(JDK1.2)- Vector:作为
List接口的古老实现类,线程安全的,效率低,底层使用Object[] elementData存储。(JDK1.0)- Set:存储无序的、不可重复的数据(JDK1.2)
- HashSet:线程不安全的,可以存储
null值(JDK1.2)
- LinkedHashSet:
HashSet的子类,HashSet基础上加了双链表,可按序遍历。对于频繁的插入、删除操作,使用此类效率比HashSet高。(JDK1.4)- TreeSet:可以照添加对象的指定属性,进行排序。(JDK1.2)
- Map:双列数据,存储
key-value对的数据(JDK1.2)
- HashMap:线程不安全的,效率高。可存储
null的key和value(JDK1.2)
- LinkedHashMap:
HashMap的子类,HashMap基础上加了双链表,可按序遍历。对于频繁的插入、删除操作,使用此类效率比HashMap高(JDK1.4)- TreeMap:可按
key进行自然排序或定制排序。(JDK1.2)- Hashtable:作为古老的实现类,线程安全的,效率低,不能存储
null的key和value。(JDK1.0)
- Properties:常用来处理配置文件。
key和value都是String类型。(JDK1.0)
¶1、List源码分析
¶1.1、ArrayList
JDK7中的
ArrayList的对象的创建类似于单例的饿汉式,而JDK8中的ArrayList的对象的创建类似于单例的懒汉式,延迟了数组的创建,节省内存。JDK7中:
ArrayList list = new ArrayList():底层创建了长度是10的Object[]数组elementData- 扩容:默认情况下,扩容为原来的容量的1.5倍,同时需要将原有数组中的数据复制到新的数组中
- 开发中建议:使用带参的构造器:
ArrayList list = new ArrayList(int capacity)
JDK8中:
ArrayList list = new ArrayList():底层Object[] elementData初始化为{},并没创建长度为10的数组- 第一次调用
add()时,底层才创建了长度10的数组,并将数据添加到elementData[0]
¶1.2、LinkedList
-
LinkedList list = new LinkedList():内部声明了Node类型的first和last属性,默认值为null -
list.add(123):将123封装到Node中,创建了Node对象。
其中Node静态内部类长这样: 体现了LinkedList的双向链表的说法!
1 | |
¶1.3、Vector
在多线程问题中,即使
vector是线程安全的,也不去用它,而去用Collections工具类的SynchronizedList方法去将ArrayList扔进去返回的就是线程安全的集合!
- JDK7和JDK8中通过
Vector()构造器创建对象时,底层都创建了长度为10的数组 - 扩容方面:默认扩容为原来的数组长度的2倍。
¶2、Set源码分析
关于存储数据无序的、不可重复的说明:
- 无序性:不等于随机性。存储的数据在底层数组中并非照数组索引的顺序添加,而是根据数据的哈希值决定的。
- 不可重复性:保证添加的元素照
equals()判断时,不能返回true即:相同的元素只能添加一个。因此,
HashSet和LinkedHashSet存储对象所在类的要求:
- 向
Set(主要指:HashSet、LinkedHashSet)中添加的数据,其所在的类一定要重写hashCode()和equals()- 重写的
hashCode()和equals()尽可能保持一致性:相等的对象必须具有相等的散列码
- 重写两个方法的小技巧:对象中用作
equals()方法比较的Field,都应该用来计算hashCode值。Set接口中没额外定义新的方法,使用的都是Collection中声明过的方法!
三个实现类底层都是以
Map存储的,详细的请看下一节的Map源码分析!
¶2.1、HashSet
七上八下存储:
- JDK 7 :元素
a放到数组中,指向原来的元素。- JDK 8 :原来的元素在数组中,指向元素
a
HashSet元素添加过程:
-
我们向
HashSet中添加元素a,首先调用元素a所在类的hashCode()方法,计算元素a的哈希值,此哈希值接着通过某种算法计算出在HashSet底层数组中的存放位置(即为:索引位置),判断数组此位置上是否已经元素: -
如果此位置上没其他元素,则元素
a添加成功。 —>情况1 -
如果此位置上其他元素
b(或以链表形式存在的多个元素),则比较元素a与元素b的hash值: -
如果
hash值不相同,则元素a添加成功。—>情况2 -
如果
hash值相同,进而需要调用元素a所在类的equals()方法:equals()返回true,元素a添加失败。equals()返回false,则元素a添加成功。—>情况3
HashSet底层实际是用HashMap存储的:
- 具体细节在下面Map源码分析中详解!
1 | |
¶2.2、LinkedHashSet
继承自
HashSet,同样底层实际使用LinkedHashMap存储!再添加数据的同时,维护了两个变量存储前后数据位置,类似双链表方式维护!
具体在
HashMap中详细讲解!
¶2.3、TreeSet
- 向
TreeSet中添加的数据,要求是相同类的对象。 - 两种排序方式:自然排序(实现
Comparable接口) 和 定制排序(Comparator) - 底层仍然是使用的
TreeMap存储
¶3、Map源码分析
Map中的key:无序的、不可重复的,使用Set存储所的key—>key所在的类要重写equals()和hashCode()
Map中的value:无序的、可重复的,使用Collection存储所的value—>value所在的类要重写equals()一个键值对:
key-value构成了一个Entry对象。
Map中的entry:无序的、不可重复的,使用Set存储所的entry
¶3.1、HashMap
JDK7中:
HashMap map = new HashMap():
- 在实例化以后,底层创建了长度是16的一维数组
Entry[] table
map.put(key1,value1):
- 首先,调用
key1所在类的hashCode()计算key1哈希值,此哈希值经过某种算法计算以后,得到在Entry数组中的存放位置。 - 如果此位置上的数据为空,此时的
key1-value1添加成功。 ---- 情况1 - 如果此位置上的数据不为空,(意味着此位置上存在一个或多个数据(以链表形式存在)),比较
key1和已经存在的一个或多个数据的哈希值:- 如果
key1的哈希值与已经存在的数据的哈希值都不相同,此时key1-value1添加成功。---- 情况2 - 如果
key1的哈希值和已经存在的某一个数据(key2-value2)的哈希值相同,继续比较:调用key1所在类的equals(key2)方法,比较:- 如果
equals()返回false:此时key1-value1添加成功。---- 情况3 - 如果
equals()返回true:使用value1替换value2。
- 如果
- 如果
- 补充:关于情况2和情况3:此时
key1-value1和原来的数据以链表的方式存储。 - 在不断的添加过程中,会涉及到扩容问题:当超出临界值(且要存放的位置非空)时,扩容。默认的扩容方式:扩容为原来容量的2倍,并将原的数据复制过来。
JDK8中与之前的不同之处:
new HashMap():底层没创建一个长度为16的数组- JDK8底层的数组是:
Node[],而非Entry[] - 首次调用
put()方法时,底层创建长度为16的数组 - JDK7底层结构:数组+链表。jdk8底层结构:数组+链表+红黑树。
- 形成链表时,七上八下(jdk7:新的元素指向旧的元素。jdk8:旧的元素指向新的元素)
- 当数组的某一个索引位置上的元素以链表形式存在的数据个数 > 8 且当前数组的长度 > 64时,此时此索引位置上的所数据改为使用红黑树存储。
HashMap底层典型属性的属性的说明:
-
DEFAULT_INITIAL_CAPACITY:HashMap的默认容量,16 -
DEFAULT_LOAD_FACTOR:HashMap的默认负载因子:0.75 -
threshold:扩容的临界值 = 容量 * 填充因子`:16 * 0.75 => 12 -
TREEIFY_THRESHOLD:Bucket中链表长度大于该默认值,转化为红黑树,8 -
MIN_TREEIFY_CAPACITY:桶中的Node被树化时最小的hash表容量,64 -
UNTREEIFY_THRESHOLD:Bucket中红黑树存储的Node小于该默认值,转化为链表 -
MIN_TREEIFY_CAPACITY:桶中的Node被树化时最小的hash表容量。(当桶中Node的数量大到需要变红黑树时,若hash表容量小于MIN_TREEIFY_CAPACITY时,此时应执行resize扩容操作这个MIN_TREEIFY_CAPACITY的值至少是TREEIFY_THRESHOLD的4倍。)
负载因子(填充比)的作用:
- 负载因子的大小决定了
HashMap的数据密度。
- 负载因子越大密度越大,发生碰撞的几率越高,数组中的链表越容易长,造成查询或插入时的比较次数增多,性能会下降。
- 负载因子越小,就越容易触发扩容,数据密度也越小,意味着发生碰撞的几率越小,数组中的链表也就越短,查询和插入时比较的次数也越小,性能会更高。但是会浪费一定的内容空间。而且经常扩容也会影响性能,建议初始化预设大一点的空间。
- 按照其他语言的参考及研究经验,会考虑将负载因子设置为
0.7~0.75,此时平均检索长度接近于常数
¶3.2、LinkedHashMap
LinkedHashMap底层使用的结构与HashMap相同,因为LinkedHashMap继承于HashMap.区别就在于:
LinkedHashMap内部提供了Entry,替换HashMap中的Node.
1 | |
¶3.3、TreeMap
- 向
TreeMap中添加key-value,要求key必须是由同一个类创建的对象! - 照
key进行排序:自然排序 、定制排序
¶3.4、Properties
是
Hashtable的子类常用来处理配置文件。key和value都是String类型!本测试不放到
main中找不到配置文件!配置文件中文乱码:打开IDEA设置的
file encoding中的Properties的勾勾!并且删掉原配置文件重新新建!配置文件新建方式:选择
Resource Bundle写入文件名回车即可! 配置文件中不要有空格!
1 | |
¶五、泛型
JDK5.0新增!
¶1、泛型注意事项
- 泛型类的构造器如下:
public GenericClass(){}。而下面是错误的:public GenericClass<E>(){} - 实例化后,操作原来泛型位置的结构必须与指定的泛型类型一致。
- 泛型不同的引用不能相互赋值:尽管在编译时
ArrayList<String>和ArrayList<Integer>是两种类型,但是,在运行时只有一个ArrayList被加载到JVM中。 - 泛型如果不指定,将被擦除,泛型对应的类型均按照Object处理,但不等价于Object。 经验:泛型要使用一路都用。要不用,一路都不要用。
- jdk1.7,泛型的简化操作:
ArrayList<Fruit> flist = new ArrayList<>(); - 泛型的指定中不能使用基本数据类型,可以使用包装类替换
- 在类/接口上声明的泛型,在本类或本接口中即代表某种类型,可以作为非静态属性的类型、非静态方法的参数类型、非静态方法的返回值类型。但在静态方法中不能使用类的泛型。(静态方法在类创建时加载时,但此时还没有造对象,T并不清楚)
- 异常类不能是泛型的
try catch(T e)也不行! - 不能使用
new E[]。但是可以:E[] elements = (E[])new Object[capacity];参考:ArrayList源码中声明:Object[] elementData,而非泛型参数类型数组。 - 父类有泛型,子类可以选择保留泛型也可以选择指定泛型类型:
- 子类不保留父类的泛型:按需实现
2. 没有类型 擦除
2. 具体类型 - 子类保留父类的泛型:泛型子类
- 全部保留
- 部分保留
- 子类不保留父类的泛型:按需实现
关于第10点的说明:
防止晕头转向,这里稍微总结一下:看每种情况后面的泛型!
1 | |
¶2、泛型方法
泛型方法:在方法中出现了泛型的结构,泛型参数与类的泛型参数没有任何关系。
换句话说,泛型方法所属的类是不是泛型类都没关系。
泛型方法,可以声明为静态的。原因:泛型参数是在调用方法时确定的。并非在实例化类时确定。
¶2.1、格式
1 | |
¶2.2、举例
1 | |
¶3、泛型在继承方面体现
- 虽然类
A是类B的父类,但是G<A>和G<B>二者不具备子父类关系,二者是并列关系。 - 补充:类
A是类B的父类(或接口),A<G>是B<G>的父类
1 | |
¶4、通配符使用
通配符:
?
- 类
A是类B的父类,G<A>和G<B>是没关系的,二者共同的父类是:G<?>
限制条件的通配符的使用:
? extends A: 上界是A。G<? extends A>可以作为G<A>和G<B>的父类,其中B是A的子类? super A: 下界是A。G<? super A>可以作为G<A>和G<B>的父类,其中B是A的父类
1 | |
 微信
微信 支付宝
支付宝


